The Thousand-Dollar Query: A Story About Effective Code Optimization
Who said you don't need math for software engineering?
APIs are great, especially if they’re from a third party that has already solved a complex problem that we might be facing at some point – who doesn’t love a good old npm install @{company_name}/sdk? Just a few steps and you’re up and running, it feels pretty much like magic.
There’s no need to reinvent the wheel… Right?

But, as wonderful as they can be, they’re also one of the easiest ways of shooting yourself in the foot – nothing is free, and everything comes at a cost, this is why, out of many alternatives & services out there in the market, there’s a non-trivial decision-making process behind most (if not all) API choices.
As someone very wise once said:
With great power, comes great responsibility.
Which holds true in the case of leveraging paid third party services.
Imagine you’re a startup founder – you have this app which you’re trying to build, hoping it’s the next breakthrough into a specific market, but you’re still not making any money off of it, hopefully investing just the necessary to get your MVP up and running. It’s in your best interest to ensure your service bills don’t skyrocket in a way that makes it impossible to even finish a product that still isn’t profitable.
If you’re not careful with the services you’re using, they will backfire. This, as obvious as it might sound, happens more often than you’d think and, in fact, it happened to me as well –or, to be clear, a project where I used to work a few years ago– when one of our services billed us way more than we anticipated, and we had to do something about it.
This is the story of how we tamed Google Cloud Platform and significantly reduced service usage costs by thinking, testing, iterating and using the power of, guess what? Math.
Let’s get technical.
Note that, for obvious privacy reasons, the story details will be kept as generic as possible in order to avoid revealing any critical/private company information.
The app
First, some context – you (and by “you” I mean “me”, at about 2 years of experience) are working on a multi-database SaaS application, targeted towards companies that handles vehicles & drivers, productivity is measured based off of driver activity, meaning, the app has to collect driver metrics (think GPS location, driving speed, idle time, etc).

The service was fully equipped with a web application made in React (targeted towards management), a server written in Node.js, and a mobile app written in, you guessed it, React Native (targeted towards drivers & other employees). The mobile app was the source of all employee activity, so there was a special focus on it, making sure it works as expected and was tracking properly at all time, sending location data that the server would then save as coordinates in a table (along with a timestamp and some other information).
In contrast, the UI-part of the system was only used by managers & HR employees, collecting & displaying all of the critical company data, which in of itself was a lot – there were performance metrics everywhere: leaderboards, charts, MTD & YTD company productivity measurements, driver activity summary & much more. One could imagine how such system relies on data aggregation gymnastics in the backend – most of the “magic” happened there and, even though the website had considerably less traffic, the processing needed in order to simply serve the dashboard data was huge.
One thing was certain – this app was way more legacy than I imagined, as the backstory goes, development started of many years before I even joined the company I worked for at that time, so most of the system behavior –although brittle & fragile– was already built. Keep this in mind, as it will come into effect once we talk about the problems that arose, quite literally, days after I joined.
One of which I still remember to this day.
Alarms go off
One day, at our daily standup (which happened pretty early in the morning for me), it was immediately brought to discussion a critical situation – a Google invoice had arrived with the monthly bill, and it was nuts, our bill had almost 10x’ed compared to last month’s, surpassing the thousands of dollars. As you might imagine, the CEO was going crazy – understandably.
Past invoices were nowhere near that price we received, clearly something wasn’t right, so we immediately started investigating.
Imagine waking up to find out your monthly bill suddenly skyrocketed… Oh, wait.
After carefully looking at the Google Cloud dashboard, we immediately found the major source of usage – the Geocoding API. We knew that, although we had various maps on the site, there were only a few places where we were using that part of the SDK, so that was our starting point.
However, let’s go back to the dashboard for a moment – there’s a special page which –in the CEO’s own words– was “specifically designed for management to keep open all day”, as it contained “real-time” updates from the ongoing shifts (you’ll see why I’m quoting it pretty soon) and, most importantly, contained a very specific widget – the Activity feed, which looked something like this:
Activity feed
Pretty simple, right? Just a list of the most recent system alerts, which were very important for management, as it was one of the main selling points of the app – a straight eye into what’s going on company-wide during the current shifts. The point of the widget is to receive updates & events from the server, and immediately reflect those updates in the client, such that a manager wouldn’t have to exit or refresh the page to continuously monitor how the drivers were doing. So far so good, however… There’s a catch.
You might’ve noticed the feed has pagination controls – pagination is great, as its purpose –more than just organizing data visually– is to help alleviate load times by only requesting the data for the current page you’re in, and load everything else as the user moves between pages. That’s how basic pagination should be implemented, right?
…right? ![]() :padme:
:padme: ![]()
Turns out, it wasn’t the case. The request at load-time would bring all data altogether, rendering the pagination completely useless (making it merely a visual thing), but it doesn’t end there – remember I purposefully quoted the so-called “real-time” part? One would assume that, after the UI loads (along with the entire list entries), newer events would just slot a new entry into state, since past events have already been loaded.
Wrong, again. As soon as a new event came in, the app would blow out the entire list and fetch everything all over again, meaning, if we had 100 events, and a new one came in, the list would be re-fetched and get 101 events back.
What?
Alright, alright, let’s step back for a moment, we have a very bad UI implementation and, arguably, a really poor update strategy, but how is this related to the billing problem? Here’s the thing – take a look again at the Activity feed, what information does each location have?
Let’s see, it has a name, a type, an address… Hold on, an address? Didn’t you just say this in the previous section?
“…sending location data that the server would then save as coordinates in a table…”
How did an address end up there if the mobile app sends only coordinates? Well, remember I mentioned something about the Geocoding API?
I think you already see where this is going.
That’s right, the database has only coordinates but the app needs addresses, and GCP’s Geocoding suite just so happens to have a service called Reverse Geocoding API, which the documentation describes as the following:
The term geocoding generally refers to translating a human-readable address into a location on a map. The process of doing the converse, translating a location on the map into a human-readable address, is known as reverse geocoding.
Instead of supplying a textual
address, supply a comma-separated latitude/longitude pair in thelocationparameter.
The app was using the Reverse Geocoding API to convert each of the alert’s attached coordinates into addresses, and remember, each time we open up the dashboard the app loads all alerts at the same time! Which means, going back to the 100 alerts example, the act of a person simply navigating into the page would then trigger 100 API calls and, if a new notification came in 5 seconds later (considering we’re re-requesting the entire list again), those would be 101 calls apart from the past 100, giving us a total of 201 API calls in a span of just 5 seconds – wasn’t this page supposed to be “safely kept open” during the entire 8 hours of the shift?
Clearly, this is bad, and things get way darker once you realize the full extent of the problem – we weren’t even at 10% of the intended usage! Just by how the system was built (considering that each client would have their own separate database) we were able to run some numbers to try and predict how the billing would scale as the user base grows, and let me tell you, it’s way worse than you could imagine.
Just to give you an idea, here’s a very high-level approximation of these numbers I came up with at the time:
I know – what the hell? Breaking down the equation we have:
-
as the total amount of requests made in a day. -
as the number of companies actively using the system, by that time, it was just us (assume 1). -
as the amount of managers that would be signed into the app monitoring the feed (our CEO was the only one constantly checking the page, assume 1 again). -
as the total hours spent watching the dashboard per day, he would spend about 4 hours at most. -
as the average alerts per hour (usually 45 or so). -
(which is within a sum from 0 up to ) is the number of Reverse Geocoding requests accumulated as the alerts come in, which is the calculation we ran before: a manager starts their shift with 0 alerts, then 1, then 2, then 3, and so on.
Plugging those numbers into the equation yields about 16,290 requests per day, convert that to a monthly basis (about 20 working days) and it’s 325,800 requests per month – Google charges about $0,004 per API call, so that gives a grand total of $1,303.2 for usage, which is roughly around what we were being charged with, and remember – it was just us! If we assumed a more broad user base of 4 companies, with 3 managers each and full 8-hour monitoring, we’d be charged approximately $31,190.4 (if we didn’t have to contact sales already for volume pricing), which is just ridiculous.
With no time to waste, we started brainstorming right away.
Initial thoughts
Alright, we had to come up with something, what are our options? The first solution that came to mind was the most obvious – fix the pagination and the notification system. There’s no discussion, this was a must, and looking into other options without considering this would’ve been pure negligence, however, there were some slight problems:
- The frontend guy gave a very broad estimate, he said he needed to “rewire” that component’s inner workings, and he would have to spend some time syncing up with the backend dev to refactor the endpoint in order to support paginated requests (I know, you’re probably screaming at this – I was too).
- The notification system worked through web sockets, and this implementation was soon to be deprecated, as the backend would transition from an EC2 instance to an auto-scalable EBS configuration, which in turn made us look into another push notification alternatives and not assume that the current state of notifications would stay around much longer.
- There were some future features that would work very similarly to this activity feed, but those wouldn’t have pagination – there were more data-heavy UI parts coming soon, and we had to be prepared for that.
This, although didn’t necessarily block the so-needed refactor, it definitely made us know that we needed to look for additional short-term measures that helped us at least alleviate the billing, while also thinking forward on how to create a consistent, budget-friendly way of handling locations.
Our CEO mentioned something that at first kinda made sense as well – can’t we pull the address along with the coordinates from the device’s GPS itself? We thought there may be a chance, but that was quickly shot down, as we found out the only way is to, guess what, call the Geocoding API from the device, and this would be even worse, as the app reports locations every 5 seconds, for an 8-hour shift that would be 5760 requests per shift, but remember, there’s way more drivers active on the road than managers checking the activity feed! About 10-15 were active by that time, if each one of them produces ~5k requests per day… I won’t even try to run those numbers.
That same day, after more brainstorming with my tech-lead at that time, some light was shed on our idea pool – a location cache table. The idea was simple: what if we could store addresses and their corresponding coordinate pairs into a table that we’d lookup whenever we needed? Database reads & writes are way cheaper than Geocoding API calls, and considering we had plans to overhaul & fix the frontend’s inefficiencies, it seemed plausible to simply create a dictionary that we could fill over time and then query just like we would with the Geocoding API.
Alright! Let’s get to wor– wait… Have you seen what coordinates look like?
{
"lat": 28.497497,
"lng": -81.275426
}You might already see what the problem is – How on earth would one simply query for a pair of numbers like that? Coordinates require floating-point precision, and GPS data is extremely granular, even if you stored all of the coordinates a driver sends during a shift, the odds of hitting the exact same pair again are extremely low. If we were to translate all of those coordinates, we would end up with almost the same usage as if we called the Geocoding API with every GPS ping.
“Let’s just trim some decimals then”, my tech-lead said, but that wasn’t an option either – for an app like this, decimal precision was an invaluable asset, as it was the key to the movement insights used to measure performance and, therefore, derive bonuses & other payroll metrics; the system needed to not only measure driving speeds, but also walking pace as well. Even if we removed 3 decimal places, we would still be in a place of highly unlikeness to have a record that matched our queries, and we’d be messing up the detection – let me illustrate.
Let’s take above’s coordinates as an example, those locate to this place in particular:
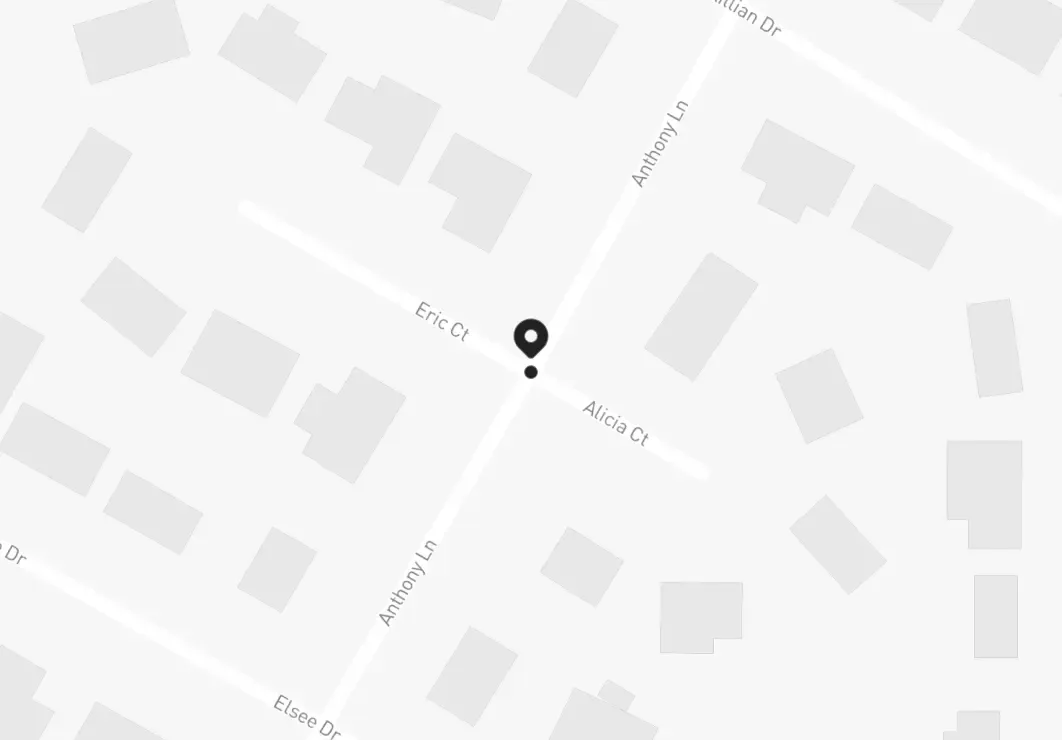
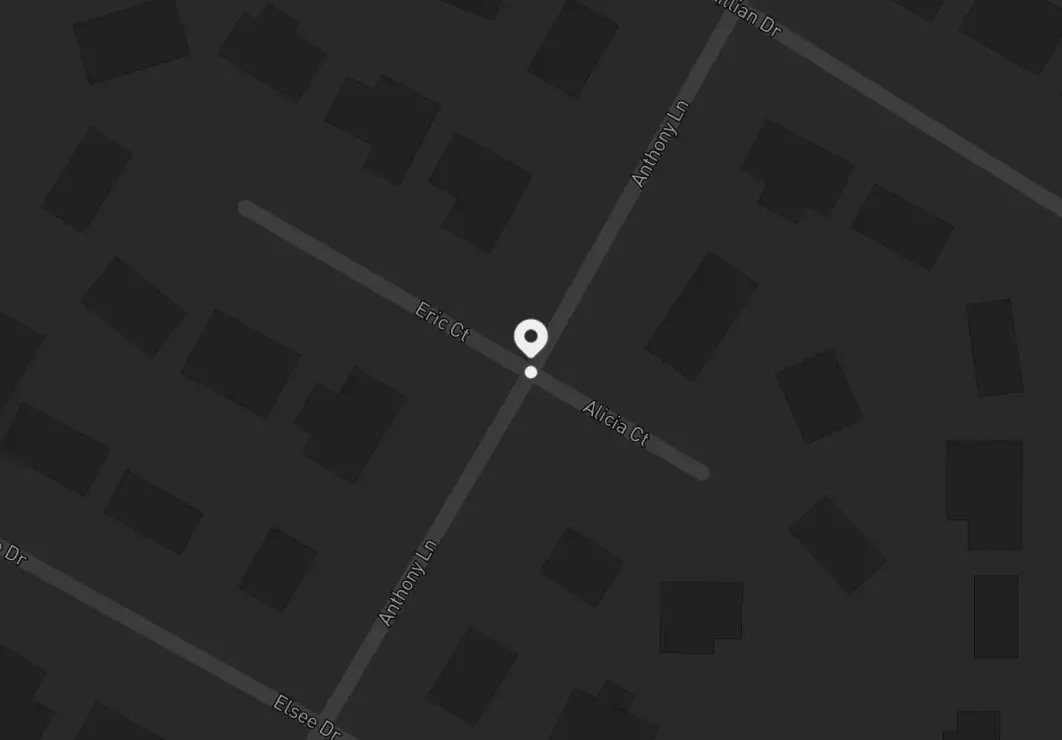
What would happen if one of the employees were walking around that area, and the app wanted to process their location but trimming the last 3 decimals? This is approximately what it would look like:
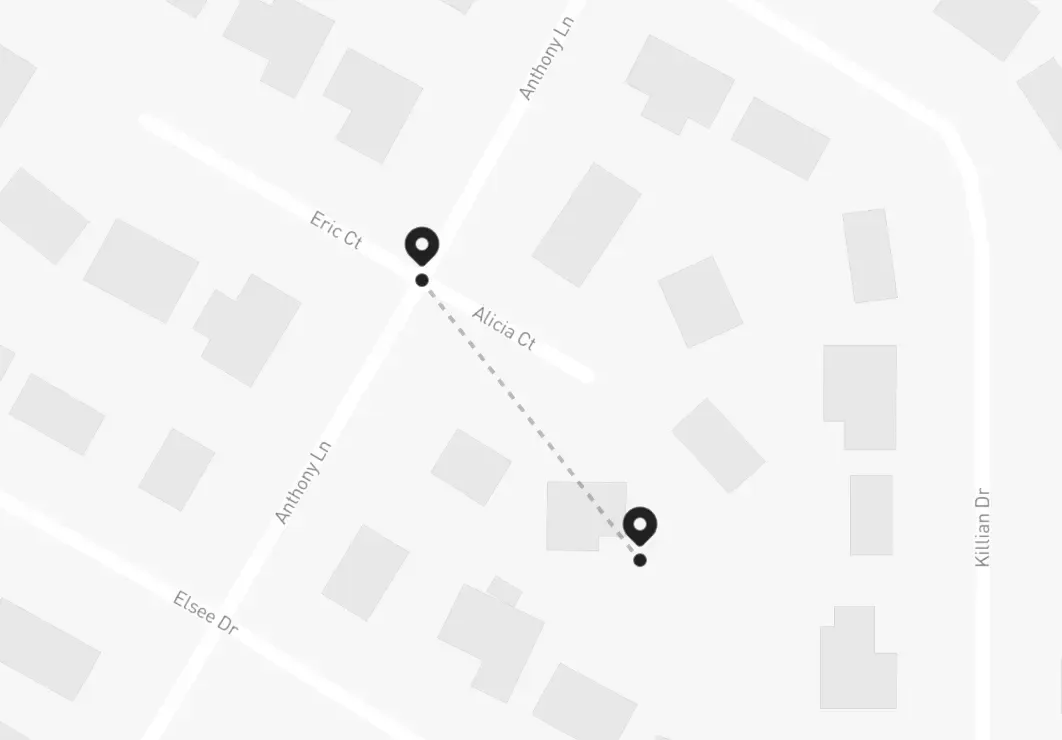
See the problem? Suddenly the person is 100 meters away from their true location, and the speed detection service would start miscalculating everything – if it took 3 decimal places to make a 100 meter difference, in the eyes of the speed measurements the person would remain still (this is, 0 m/s) for about 2 minutes before –seemingly out of nowhere– spawning 100 meters apart from their last position, making it look like they moved at 100 m/s before going back to being still again:
We haven’t invented teleportation yet.
Regardless, I still liked the idea of the lookup table – it would be really, really convenient to have a centralized place that collected the addresses just once and we could use it everywhere and avoid hitting the Geocoding API more than the necessary, but we have this inevitable wall when trying to intuitively use whatever information was stored there due to the problem of querying with no exact matches…
“…Exact matches…” – wait.
I had an idea.
Geometry to the rescue
My mind was speeding at 1000mph, blood pumping through my veins like engine oil, thoughts insanely revolving this idea that hit my head like a bullet train – everything was clear now.
It doesn’t «have» to be exact.

What if we could “fuzz-out” the search and expand it to get the nearest stored point to our location? That way, we would have way more chances of finding a match, and we would have total control over how close we want those points to be, just so we can predictably assume an error tolerance that worked for us without compromising accuracy over the speed calculations.
We could then safely follow the cache table workflow, which would go something like this:
- Receive a
location, search it insidestored_locations. - If we don’t get a match, call the Reverse Geocoding API and store both the
locationand theaddress, return that result. - If we do get a match, just return it.
Sit tight, I’m going full Wikipedia now.
We now just need a way to measure distance between two coordinate pairs on a spherical surface as our filter function which, fortunately, we already have – the Great-circle distance:
Where
Where


And the best part? It’s just a query change! This filter can be shoved inside our data-access layer by adding the third term distance as the equation result to our query, paired with a HAVING clause that sets a clear threshold for the search radius we’re going after – this would end up looking something like this:
SELECT latitude,
longitude,
ACOS(SIN(latitude) * SIN(:lat) + COS(latitude) * COS(:lat) * COS(ABS(longitude - :lng))) * 6378160 AS distance
FROM stored_locations
HAVING distance < :distance
ORDER BY distance; We found 25 meters to be the sweet spot for setting a threshold radius trough :distance, and we could also throw in a LIMIT 1 since we only care about the closest match and, worst case scenario, we would only be 25 meters off from the address calculation (not the speed or geographical position, like with the decimal trimming approach). That’s it!
I quickly drafted a PR, got it through all they way up to the staging environment, immediately started testing with the ongoing shifts, and waited patiently – this was the initial cold run, the database was completely empty, but right away started filling up with locations and their corresponding addresses from all the current drivers, so I was expecting some sort of high usage for that day. To better evaluate the performance, I created a log stream that would keep track of database & API hits by day, just so I could measure the progress afterwards.
Needless to say, I went all-in on this approach – I had run all the calculations in my head, it should work but, still, I was pretty nervous.
After that really painful night, next day came in…
No amount of overthinking prepared me for what I’d find – we were already down to about 65% of past day’s usage. This was huge, and the best part is, it would only keep decreasing:
- Most drivers had recurrent routes as each one had a designated area, sites they’d go over by routine.
- They would also had a set of company-wide common places to drive by.
- The company’s scope was limited to only their city & small amounts of surrounding places, there would be no randomly driving to the other side of the state.
And these facts hold true for the companies that this system targets as well. Two weeks later, we were at just below 15% of the usage, and it kept consistently decreasing even more and more – by the end of the month, we were charged with only $183 or so, meaning, we had successfully saved ~86% of past month’s bill:
Note that these graphs are just an approximation to the call history from back then, as I don’t have access to that project and/or its resources anymore.
This trend continued and settled at around 10% of that awful bill’s pricing for the next month’s usage, effectively saving the company 90% in Google’s API cost. It’s worth mentioning that the bill will still increase as new companies join the system & start tracking drivers, but in a very reduced fashion thanks of to improvements in that page, as the component was eventually fixed, completely detaching the API usage from that page’s activity. Hooray! 🎉
Management was happy, the CEO was grateful, and we continued pushing performance further and further around the entire application – at least during the next 5 months I worked there before leaving the company.
I could talk about how I took that same page’s load time from two minutes to just 7 seconds, though…
But that’s another story.
Above and beyond
Granted, the web ecosystem moves at giant steps every day that passes, and this solution –although useful at that time– may not have been the best, we were very time constrained and had to act quickly. API refactors like this should be carefully studied and definitely planned-out ahead of time.

Maybe there’s a library that already does this, perhaps there’s another way in which we could have stored the data & queried for it that was more efficient. Knowing & using those equations wasn’t any kind of “breakthrough” to be honest. If anything, the only thing I sort of did was figuring out how “places near me” recommendations work.
Still, to this day I keep thinking about other ways we could’ve approached this problem differently – what if we used another service? What if there was a way to call the API even less? How can we reduce the strain of adding new companies and avoid having to let them fill-in their locations manually? As with everything in programming, the possibilities are endless, and there’s no single way to solve a problem.
One thing is certain, though – had we not acted quickly and tried our best to craft a reasonable solution, this issue would’ve caused pretty serious damage the project. Thankfully, some equations and a bit of abstract thinking were the nails in the coffin of this awful situation.
Who said you don’t need math for software engineering?
Continue reading
Do we really know what goes into effective knowledge sharing?
What happens when the stress doesn't go away?
What is it like to be the one asking the questions?